data:text/html;charset=utf-8;base64: korrekt kodieren, sicher ausliefern, performant einsetzen
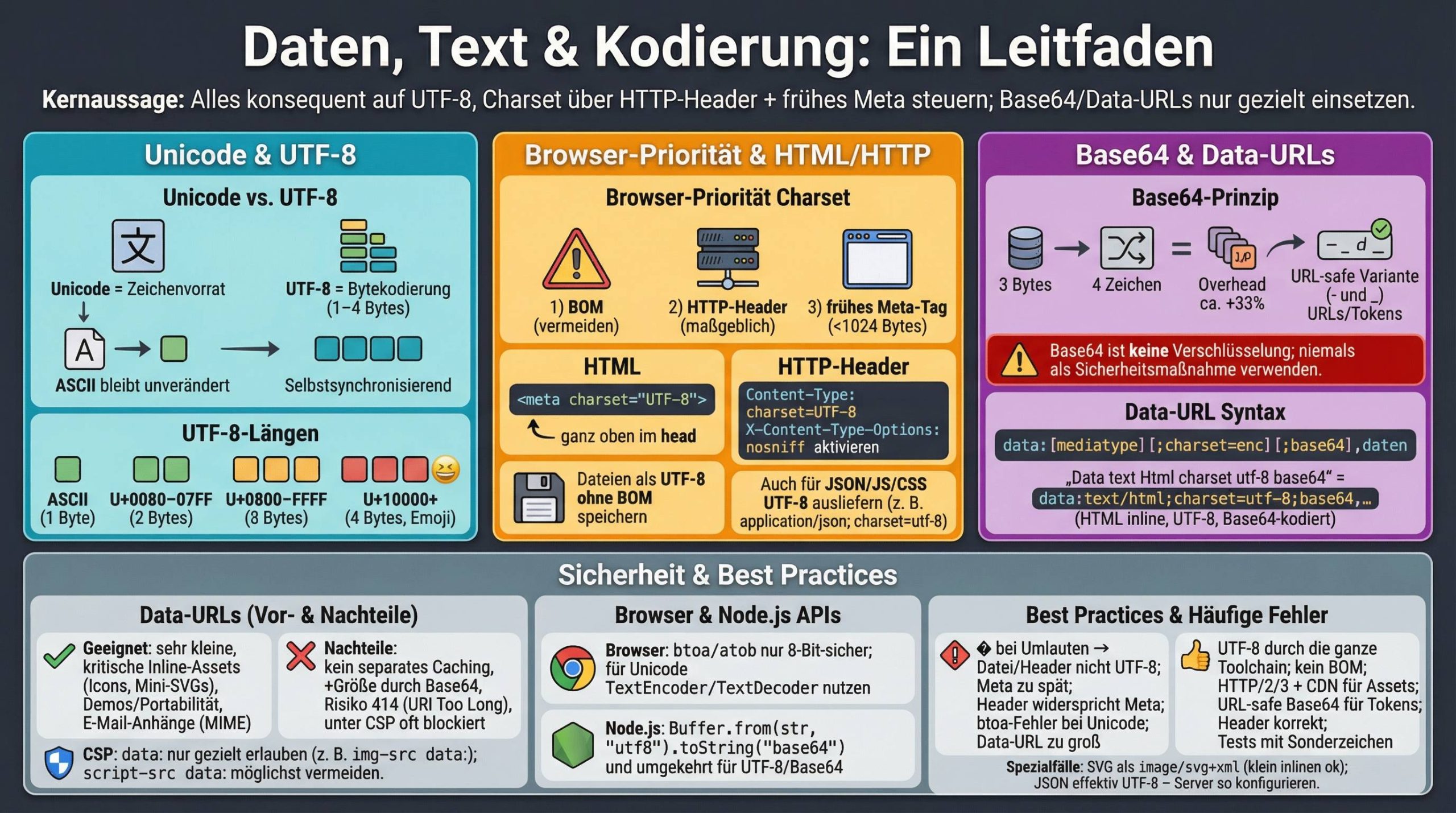
Zeichenkodierung und binär‑zu‑Text‑Kodierung sind Grundlagen, die jede Webapp betreffen: vom Rendering der Umlaute bis zur Einbettung von Assets in eine einzige HTML-Datei. In diesem Leitfaden zeige ich dir kompakt und praxisnah, wie du UTF‑8 in HTML korrekt deklarierst, wie Base64 funktioniert, wo Data‑URLs sinnvoll sind – und wo nicht. Das häufig gesuchte Stichwort Data text Html charset utf-8 base64 ordne ich dabei konkret ein und liefere dir belastbare Best Practices, Codebeispiele und Fallstricke aus der Praxis.
Kernaussage: Stelle deine HTML-Seiten, APIs und Assets konsequent auf UTF‑8 ein, kontrolliere die Zeichenkodierung über HTTP-Header und Meta-Tags, und nutze Base64/Data‑URLs gezielt für Spezialfälle – nicht als Allheilmittel.
Warum Zeichenkodierung zählt – und was Unicode/UTF‑8 wirklich leisten
Unicode ist der globale Zeichensatz, der jedem Zeichen eine eindeutige Nummer (Codepoint) zuweist. UTF‑8 ist die Kodierung, die diese Codepoints als Folge von 1 bis 4 Bytes darstellt. Der Clou: ASCII (0–127) bleibt unverändert, viele westliche Texte belegen dadurch pro Zeichen nur 1 Byte, während z. B. Emojis mehrere Bytes nutzen.
- Rückwärtskompatibel zu ASCII: Bestehende Tools kommen klar.
- Speichereffizient für westliche Sprachen, universell für alle Sprachen.
- Selbstsynchronisierend: Decoder finden Byte‑Grenzen robust, was Suche, Parsen und Fehlerbehandlung erleichtert.
| Zeichenbereich (Unicode) | UTF‑8‑Länge | Beispiel |
|---|---|---|
| U+0000 – U+007F | 1 Byte | a, A, 0–9, Standard-ASCII |
| U+0080 – U+07FF | 2 Bytes | é, ü, ß, viele europäische Akzente |
| U+0800 – U+FFFF | 3 Bytes | Arabisch, Hebräisch, Kyrillisch, viele CJK‑Zeichen |
| U+10000 – U+10FFFF | 4 Bytes | Emoji, seltene historische Schriften |
Merke: Unicode ist das Alphabet, UTF‑8 die Schreibweise. Du speicherst Dateien in UTF‑8 – und deklarierst das sauber, damit Browser/Clients sie korrekt interpretieren.
HTML: charset korrekt setzen – von HTTP bis Meta-Tag
Für konsistentes Rendering musst du die Zeichenkodierung eindeutig deklarieren und mit dem tatsächlichen Datei-Encoding abgleichen.
Die drei relevanten Ebenen
| Priorität | Quelle | Beispiel | Hinweise |
|---|---|---|---|
| 1 (höchste) | BOM (Byte Order Mark) | UTF‑8 BOM am Dateianfang | Für Web eher vermeiden; kann in JS/CSS stören |
| 2 | HTTP‑Header | Content-Type: text/html; charset=UTF‑8 | Autoritativ; vom Server gesendet |
| 3 | HTML‑Meta | <meta charset=“UTF-8″> | Muss in den ersten 1024 Bytes stehen |
Praktische Beispiele
Empfohlenes Meta‑Tag (HTML5):
<!doctype html>
<html lang="de">
<head>
<meta charset="UTF-8">
<title>Beispiel</title>
</head>
<body>…</body>
</html>
HTTP‑Header setzen (Beispiele):
- Apache (.htaccess):
AddDefaultCharset UTF-8 - Nginx (Server-Block):
add_header Content-Type "text/html; charset=UTF-8"; - Express/Node.js:
res.type("html; charset=utf-8").send(html) - PHP:
header("Content-Type: text/html; charset=UTF-8");
Tipps: Speichere die Datei tatsächlich als UTF‑8 (ohne BOM), setze den HTTP‑Header korrekt, und platziere das Meta‑Tag ganz oben im <head>. Aktiviere optional X-Content-Type-Options: nosniff, um Browser-Sniffing zu unterbinden.

Base64: Binär zu Text – so funktioniert die Umwandlung
Base64 verwandelt beliebige Bytes in druckbare Zeichen. Jede 3‑Byte‑Gruppe (24 Bit) wird zu 4 Base64‑Zeichen (je 6 Bit). Passt die Eingabe nicht glatt in 3 Bytes, dient = als Padding.
- Alphabet: A–Z, a–z, 0–9, +, /
- URL‑safe Variante:
+→-,/→_(kein Padding oder=optional) - Overhead: etwa +33% Datenvolumen (ohne Zeilenumbrüche)
Beispiel ("hello"):
Original (ASCII/UTF-8 Bytes): 68 65 6C 6C 6F
Base64: aGVsbG8=
| Input‑Bytes | Base64‑Zeichen | Kommentar |
|---|---|---|
| 3 | 4 | ideales Verhältnis |
| 2 | 4 | ein = Padding |
| 1 | 4 | zwei = Padding |
Wichtig: Base64 ist keine Verschlüsselung; es ist eine reversible Kodierung. Vertrauliche Daten gehören nicht als Base64 in öffentlich sichtbare Orte (HTML, URLs, Logs).
Data‑URLs: Inline‑Daten in HTML/CSS/JS
Data‑URLs betten Daten direkt in die Seite ein. Syntax:
data:[<mediatype>][;charset=<enc>][;base64],<daten>
- Mediatyp: z. B.
image/png,text/html,image/svg+xml - charset: sinnvoll bei text/* (z. B. UTF‑8)
- base64: Marker, dass der Datenblock Base64‑kodiert ist
Beispiele:
Inline‑Bild als <img>:
<img alt="Icon"
src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAUA…"/>
Kleines HTML‑Snippet als eigenständige Seite (z. B. in einem <iframe>):
<iframe
src="data:text/html;charset=utf-8;base64,PGh0bWw+PGJvZHk+SGFsbG8hPC9ib2R5PjwvaHRtbD4="
width="300" height="120"></iframe>
Genau diese Kombination beschreiben viele als Data text Html charset utf-8 base64. Hier ist sie korrekt umgesetzt: data:text/html;charset=utf-8;base64,...
CSS‑Hintergrundbild (z. B. kleines SVG):
.logo {
background-image: url("data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg' width='24' height='24'>...</svg>");
}
Hinweise:
- Caching: Data‑URLs werden nicht separat gecacht. Wiederholte Nutzung bläht HTML/CSS auf.
- Performance: Für sehr kleine, kritische Assets okay; größere Dateien lieber extern laden (HTTP/2/3 ist effizient).
- CSP: Eine strikte Content Security Policy blockt
data:oft standardmäßig. Erlaubnisse gezielt setzen (z. B.img-src data:).
JavaScript: btoa/atob, Unicode‑sicher kodieren, und Node‑Alternativen
Browser (btoa/atob)
btoa() kodiert binäre Daten zu Base64, atob() dekodiert Base64 zu einem String aus 8‑Bit‑Bytes. Achtung: btoa() erwartet latin1/ASCII‑kompatible Eingaben.
// Einfacher Fall (ASCII):
btoa("hello") // "aGVsbG8="
atob("aGVsbG8=") // "hello"
Unicode‑sichere Variante mit TextEncoder/TextDecoder:
// UTF-8 → Base64
function toBase64Utf8(str) {
const bytes = new TextEncoder().encode(str);
let bin = "";
bytes.forEach(b => bin += String.fromCharCode(b));
return btoa(bin);
}
// Base64 → UTF-8
function fromBase64Utf8(b64) {
const bin = atob(b64);
const bytes = Uint8Array.from(bin, c => c.charCodeAt(0));
return new TextDecoder().decode(bytes);
}
// Test:
const s = "Grüße 👋";
const b64 = toBase64Utf8(s); // z. B. "R3LDvHNlIPCfk6k="
fromBase64Utf8(b64) === s; // true
Node.js (Buffer‑API)
// UTF-8 → Base64
const b64 = Buffer.from("Grüße 👋", "utf8").toString("base64");
// Base64 → UTF-8
const str = Buffer.from(b64, "base64").toString("utf8");
Blob/File → Base64 (Browser)
async function blobToBase64(blob) {
return await new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onload = () => resolve(reader.result.split(",")[1]); // nur der Base64-Teil
reader.onerror = reject;
reader.readAsDataURL(blob); // erzeugt data:[mime];base64,<...>
});
}
async function urlToDataUrl(url) {
const res = await fetch(url);
const blob = await res.blob();
return await new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onload = () => resolve(reader.result); // komplette data:URL
reader.onerror = reject;
reader.readAsDataURL(blob);
});
}

Sicherheit: Encoding‑Differentials, XSS und CSP
Fehlerhafte oder uneinheitliche Zeichenkodierung kann Sicherheitslücken verursachen:
- Encoding Differential: Serverseitige Validierung/Sanitization erfolgt in einer anderen Kodierung als die clientseitige Interpretation – im Worst Case wird schädlicher Input nicht korrekt neutralisiert.
- Überlange UTF‑8‑Sequenzen: Moderne Parser lehnen sie ab; trotzdem gilt: Eingaben strikt validieren, Ausgaben korrekt kontextualisiert escapen (HTML, Attribute, JS, CSS, URL), und die Kodierung überall konsistent halten.
- Data‑URLs: Erlaube
data:nur wo nötig.script-src data:ist riskant und meist unnötig. Nutze eine restriktive CSP.
Empfehlungen:
- Erzwinge UTF‑8 per HTTP‑Header auf allen HTML/JSON/JS/CSS‑Antworten.
- Setze
X-Content-Type-Options: nosniffund korrekt gesetzteContent-Type‑Header. - Nutze
Content-Security-Policyrestriktiv; erlaubedata:nur für Bilder/Schriften, falls wirklich nötig.
Wann Base64/Data‑URLs sinnvoll sind – und wann nicht
Base64 ist praktisch, aber kein Standard‑Werkzeug für alles.
Geeignet
- Kleine Inline‑Assets (Icons, 1×1‑Pixel, Mini‑SVGs) in kritischem CSS/HTML, um zusätzliches Round‑Trip‑Latency zu vermeiden.
- E‑Mail (MIME): Anhänge, die über 7‑Bit‑Transport laufen müssen.
- Portabilität/Demos: Selbstenthaltende Beispiele, Gists, reproduzierbare Test‑HTMLs.
Nicht geeignet
- Größere Assets (Bilder, Fonts, Videos): +33% Overhead, kein separates Caching, erschwertes Cache‑Invalidieren.
- Sicherheitskritische Inhalte: Data‑URLs können Policies umgehen, sind schwer zu auditieren. Lieber klare Ressourcenpfade und CSP.
- SEO/Analytics: Inlined Assets erschweren Metriken und CDNs; externe Ressourcen sind transparenter und besser optimierbar.
Häufige Fehler und schnelle Diagnosen
- Umlaute zeigen �: Datei ist nicht als UTF‑8 gespeichert. Lösung: Editor/Build auf UTF‑8 umstellen; neu speichern; HTTP‑Header prüfen.
- Meta‑Tag zu spät:
<meta charset>erst nach anderen Tags. Lösung: Direkt am Anfang des<head>. - HTTP‑Header widerspricht Meta: Server schickt ISO‑8859‑1, Meta sagt UTF‑8. Lösung: Header korrigieren; Header hat Vorrang.
- Base64 in URL führt zu 414 (URI Too Long): Data‑URL zu groß. Lösung: Externe Datei nutzen.
btoawirft Fehler bei Unicode: Falsche Eingabe. Lösung:TextEncoder/TextDecodernutzen (siehe oben).
Pragmatische Best Practices (Checkliste)
- Alles UTF‑8: Quellcode, Templates, Backend‑Strings, DB‑Verbindungen, Datenbank‑Kollation.
- HTTP‑Header: Für
text/html,application/json,text/css,application/javascriptviacharset=UTF-8ausliefern. - Meta früh:
<meta charset="UTF-8">in den ersten 1024 Bytes. - Kein BOM für Web‑Assets, außer du weißt genau, was du tust.
- Base64 gezielt: Nur für kleine Critical‑Path‑Assets; sonst externe Dateien + HTTP/2/3 + Caching/CDN.
- URL‑safe Base64 für Tokens/URLs verwenden (
-,_statt+,/), wenn innerhalb von URLs. - CSP:
img-src data:optional;script-src data:nach Möglichkeit vermeiden. - Sanitization/Encoding: Server‑ und Client‑Seite konsistent; Kontexte beachten (HTML, Attribute, JS, CSS, URL).
Praxisnahe Code‑Snippets für den Alltag
HTML‑Skelett mit korrekter Kodierung
<!doctype html>
<html lang="de">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>UTF‑8 und Base64 korrekt einsetzen</title>
<meta http-equiv="Content-Security-Policy" content="default-src 'self'; img-src 'self' data:; object-src 'none'; base-uri 'none';">
</head>
<body>
<h1>Hallo, UTF‑8!</h1>
<p>Grüße 👋 – korrekt kodiert und ausgeliefert.</p>
</body>
</html>
Data‑URL on the fly generieren (Browser)
async function fileToDataUrl(input) {
if (!input.files[0]) return;
const file = input.files[0];
const reader = new FileReader();
reader.onload = () => {
const dataUrl = reader.result; // z. B. "data:image/png;base64,iVBORw0K..."
console.log(dataUrl);
};
reader.readAsDataURL(file);
}
Server: Einheitliche UTF‑8‑Auslieferung
// Express.js
app.use((req, res, next) => {
res.setHeader("X-Content-Type-Options", "nosniff");
next();
});
app.get("/", (req, res) => {
res.set("Content-Type", "text/html; charset=utf-8");
res.send("<!doctype html><meta charset='utf-8'>Grüße 👋");
});
Typische Sonderfälle und Feinheiten
- SVG: Als
image/svg+xmlist es textbasiert. Für sehr kleine SVGs lohnt sich Inlining; ansonsten externe Dateien mit Caching. - JSON: Meist ohne
charsetdeklariert, aber effektiv UTF‑8. Stelle sicher, dass dein Server/Framework UTF‑8 sendet. - E‑Mail (MIME): Für Textteile
Content-Type: text/plain; charset=utf-8und für BinäranhängeContent-Transfer-Encoding: base64. - Formulare: UTF‑8 für Seiten und Server‑Parser ist am robustesten; bei URL‑Encoding (application/x-www-form-urlencoded) sicherstellen, dass Server UTF‑8 erwartet.
Fazit
UTF‑8 ist der De‑facto‑Standard für moderne Webprojekte – effizient, universell und robust. Stelle deine Toolchain durchgängig auf UTF‑8 ein, deklariere die Kodierung über HTTP‑Header und ein frühes <meta charset="UTF-8">, und vermeide BOM in Web‑Assets. Base64 und Data‑URLs sind nützliche Bausteine, wenn du kleine, kritische Assets inline halten oder Binärdaten in textbasierte Kanäle bringen willst. Behalte dabei den Overhead, das fehlende Caching und Sicherheitsrichtlinien (CSP) im Blick. Mit klaren Regeln – UTF‑8 überall, Base64 gezielt, Header korrekt – vermeidest du Rendering‑Fehler, Sicherheitsprobleme und Performance‑Kosten.
FAQ
Ist Unicode das Gleiche wie UTF‑8?
Nein. Unicode ist das universelle Repertoire (Codepoints), UTF‑8 ist eine konkrete Kodierung dieser Codepoints in Bytes. Du speicherst Dateien in UTF‑8, um Unicode‑Zeichen korrekt abzubilden.
Welcher Mechanismus bestimmt am Ende die Kodierung im Browser?
Reihenfolge: 1) BOM (falls vorhanden), 2) HTTP‑Header (Content-Type: ...; charset=...), 3) frühes HTML‑Meta‑Tag, 4) Fallback/Heuristik (z. B. Windows‑1252). Der HTTP‑Header ist maßgeblich, wenn kein BOM gesetzt ist.
Warum sollte ich kein UTF‑8‑BOM in Web‑Assets nutzen?
Ein BOM kann bei JavaScript/CSS Probleme verursachen und ist im Web selten nötig. Für HTML ist es meist unkritisch, aber der allgemein empfohlene Weg ist UTF‑8 ohne BOM.
Erhöht Base64 immer die Größe?
Ja, etwa um 33%. Zusätzliches Padding kann anfallen. Für kleine Assets ist das oft tolerierbar; für größere Ressourcen ist externes Laden besser.
Ist Base64 eine Form der Verschlüsselung?
Nein. Base64 ist lediglich eine Lesbarkeits‑/Transportkodierung. Jeder kann sie zurückwandeln. Vertrauliche Daten müssen verschlüsselt werden (TLS, Kryptografie), nicht nur Base64‑kodiert.
Wann ist eine Data‑URL sinnvoll?
Bei sehr kleinen, kritischen Assets (z. B. Icons) zur Reduktion von Round‑Trips. Für größere Inhalte, wiederverwendete Ressourcen oder dort, wo Caching wichtig ist, sind externe Dateien vorzuziehen.
Wie kodiere ich Unicode sicher in Base64 im Browser?
Nutze TextEncoder und TextDecoder (siehe Beispiel oben). btoa() erwartet 8‑Bit‑Daten und scheitert bei Unicode, wenn du es direkt fütterst.
Wo setze ich die Kodierung in einer API?
Im HTTP‑Header, z. B. Content-Type: application/json; charset=utf-8. Achte darauf, dass die eigentlichen Bytes ebenfalls UTF‑8 sind (Server‑Frameworks korrekt konfigurieren).
Was bedeutet die Zeichenkette „Data text Html charset utf-8 base64“ konkret?
Sie bezieht sich auf Data‑URLs, die HTML inline enthalten, z. B. data:text/html;charset=utf-8;base64,<...>. Das sagt: Mediatyp text/html, Kodierung utf-8, Daten sind Base64‑kodiert.
Wie verhindere ich Kodierungsprobleme in der Build‑Pipeline?
Setze Editor/IDE, Linter, Bundler, Templating, Git und CI/CD konsequent auf UTF‑8. Prüfe Header mit Tools wie curl -I, inspiziere Dateien mit file oder iconv, und automatisiere Tests, die Sonderzeichen/Emoji enthalten.



Kommentar abschicken